
Bestätigt COVID-19 Fällen sind nun vergangen 10 Millionen: was werden Sie nächste Woche, weltweit und in Ihrem Land?
Eine gute Schätzung kann dazu beitragen, die Gesundheit, die Behörden mit Ihren Antworten und führen die Regierungen, wie Sie einfache sperren verfügen. Zu diesem Zweck haben wir die Veröffentlichung der Echtzeit-Prognosen für bestätigte Fälle und Todesfälle sind für viele Teile der Welt auf einer fast täglichen basis seit März 20. Diese wurden weitgehend zuverlässige Indikatoren was erwartet werden kann, zu passieren, in der nächsten Woche.
Viele der mehr formalen Modelle für die Vorhersage der Pandemie—wie in der allgemein veröffentlichten Imperial College London-Modell, unter dem die britische Regierung Antwort—verwenden Mathematik, um zu versuchen zu erklären, die zugrunde liegenden Prozesse der Ausbruch, und Sie tun dies durch die Annahme einer kleinen Anzahl von interpretierbaren Parameter (wie die R-Nummer). Sie machen Prognosen basieren auf dem Verständnis, wie Ausbrüche der Arbeit im Allgemeinen.
Unsere Prognosen, auf der anderen Seite, versucht nicht zu verstehen, warum Veränderungen auftreten. Stattdessen sind Sie rein auf Basis von Daten aus der aktuellen Pandemie, schauen, wie es hat bereits entwickelt und verschoben, um vorherzusagen, was als Nächstes passieren wird. Dies führt oft zu mehr genaue Vorhersagen.
Warum epidemiologischen Modelle können kämpfen
Stellen Sie sich vor Sie Reisen mit dem Auto von Boston nach Kalifornien. Sie wissen aus früheren Reisen, dass Kalifornien ist Ihr Ziel, wir verfolgen deine Reise und versuchen zu prognostizieren, jeder Tag Reiseroute. Wann gibt es Straßensperren, die Sie kurz Umweg, so dass unsere Prognosen schief gehen für eine Weile, dann wiederherstellen. Viele Modelle haben so eine eingebaute “reversion to the mean”, die verarbeiten kann diese Art von kleinen änderungen.
In der Regel ist dieses Modell gut funktioniert. Was aber, wenn Sie hören, über die Waldbrände in Kalifornien und entscheiden, zu Besuch in Kanada statt? Die Prognosen werden immer schlechter, wenn wir behaupten, daß Sie immer noch in Kalifornien. Das Modell braucht, um zu erholen sich von solchen “strukturellen Bruch”.
Die meisten Modelle in den Sozialwissenschaften und Epidemiologie eine Theorie dahinter, dass die Basis der verfügbaren Evidenz aus der Vergangenheit. Diese einfache Reise-Beispiel zeigt, warum solche Modelle kann nicht gut sein, um voraussagen zu machen: die Gefahr, dass Sie zu hoch getrieben durch die theoretische Formulierungen wie, dass Sie gehen nach Kalifornien.
Das Office for Budget Responsibility Vorhersagen der britischen Produktivität nach der Finanzkrise 2008 sind ein großartiges visuelles Beispiel dafür, was passiert, wenn solche Modelle auch schief gehen. Sehen Sie die schönen Grafiken zur Verfügung, die aus Ihrer historischen Prognose-Datenbank. Wir nennen Sie Igel-Graphen, denn die Wild fehlerhafte Prognosen, die Aussehen wie Stacheln Weg von der bestätigten Daten.
In der Epidemiologie, die meisten Modelle haben eine solide theoretische Grundlage. Sie berücksichtigen Epidemien beginnen langsam, dann exponentiell zunehmende und schließlich zu verlangsamen. Allerdings ist das menschliche Verhalten und politische Reaktionen führen können abrupte änderungen, die schwierig sein kann, zu ermöglichen (wie unerwartet in Kanada). Die Daten können auch plötzlich Verschiebung im Falle einer Pandemie—ramp-up-Tests können zeigen viele neue Infektionen oder Fälle, in Pflegeheimen kann plötzlich join the dataset. Um wirksam zu sein in solchen Einstellungen, Prognose Geräte müssen robust genug sein, um den Umgang mit Problemen der sich ändernden trends und plötzliche Verschiebungen in den Ergebnissen und Messungen. Unsere kurzfristigen Prognosen kann damit umgehen in einer Weise, die mehr formalen Modellen oft nicht.
Wie unsere Prognosen arbeiten und führen
Zu erstellen unsere Prognosen sagen, für die Gesamtzahl der COVID-19 Fällen, in einem Land—zuerst erstellen wir die Trendlinien auf Basis der rückgemeldeten Daten, die wir haben. Jedes mal, wenn ein neuer Datenpunkt Hinzugefügt wird, schafft dies einen neuen trend-line—, so gibt es so viele Trendlinien, wie es Datenpunkte. Ein machine-learning-Algorithmus wählt dann die trends, die die Materie aus all denen zur Verfügung, und diejenigen, die es wählt gemittelt werden, um zu zeigen, wie der Prozess sich entwickelt hat im Laufe der Zeit (der trend in den Daten). Prognosen leiten sich von diesem trend, sowie durch den Blick auf die Lücke, die zwischen früheren Prognosen und den tatsächlichen Ergebnissen.
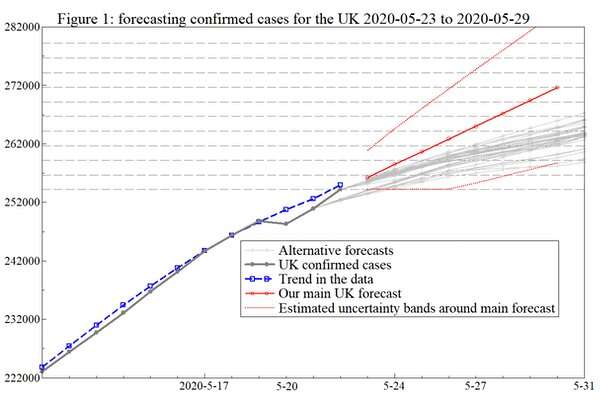
Es mag überraschen, aber dies funktioniert. Die Grafik unten zeigt die Prognose, die wir gemacht am Mai 22, wie Großbritannien die Gesamtzahl der COVID-19 Fällen erhöhen würde, im Laufe der nächsten Woche oder so (die rote, durchgehende Linie). Unsere Prognose für den 30. Mai war knapp 272,000. Das berichtete Ergebnis endete als 272,826.
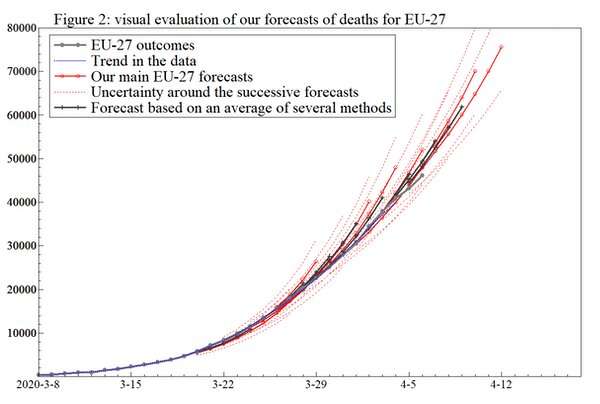
Diese zweite Grafik zeigt die Prognosen der EU-COVID-19 Todesfälle, die wir im März und April. Die sukzessiven Prognosen im Laufe der Zeit sind in rot dargestellt, die mit dem eigentlichen Daten-Punkte in Grau. Die überlappung zwischen den grauen und roten Linien zeigt, dass die Vorhersage hier war ziemlich genau. Vergleichen Sie die enge Bündelung der Linien hier, um die Igel Graphen bereits erwähnt!
Jedoch, eine genauere Art der Beurteilung der Genauigkeit der Prognosen zu betrachten, der ein Maß genannt mean absolute error (MAE). Absolute Fehler sind die numerischen Unterschiede zwischen Vorhersagen und die tatsächlichen Werte herausstellen; MAE ist der Durchschnitt dieser Differenzen für einen festgelegten Zeitraum. MAE gibt ein Allgemeines Maß dafür, wie weit Weg Ihre Vorhersagen waren.
Bis zum 4. April, die MAE für unser ” one-week-ahead-Prognosen für COVID-19 Todesfälle in einer Reihe von hauptsächlich europäischen Ländern war 629, in der Erwägung, dass im Durchschnitt die Prognosen von Imperial College London COVID-19-Antwort-Team für Todesfälle in die gleichen Länder in der gleichen Periode durch 1.068 HM. Bei der Einbindung der folgenden Woche die Daten, im Durchschnitt unsere Prognosen waren um etwa den gleichen Betrag—678—in der Erwägung, dass Imperial MAE hatte gewachsen, um 1,912. Nach April 11, unsere MAE-zahlen begann zu spiegeln des anderen, aber zumindest in den frühen Phasen der Pandemie, unsere Prognosen zu sein schien mehr genau.






