Eine neue Studie über die meta-reinforcement learning-algorithmen hilft uns zu verstehen, wie das menschliche Gehirn lernt, sich anzupassen, um Komplexität und Unsicherheiten, die beim lernen und Entscheidungen treffen. Ein Forscherteam, geführt von Professor Sang Wan Lee am KAIST gemeinsam mit John O ‘ Doherty am Caltech gelungen, zu entdecken, sowohl eine rechnerische und neuronale Mechanismus für die menschliche meta-reinforcement learning eröffnet die Möglichkeit der Portierung wesentliche Elemente der menschlichen Intelligenz in der künstlichen Intelligenz. Diese Studie bietet einen Einblick in, wie könnte es letztlich computergestützte Modelle, um reverse Engineering human reinforcement learning.
Diese Arbeit wurde veröffentlicht am Dec 16, 2019 in der Fachzeitschrift “Nature Communications”. Der Titel des Papiers ist “Task-Komplexität interagiert mit state-space Unsicherheit in der Schlichtung zwischen model-based und model-free-learning.”
Human reinforcement learning ist ein inhärent komplexer und dynamischer Prozess, der mit Zielsetzung, Strategie, Auswahl, Aktion, Auswahl -, Strategie-änderung, die kognitive Ressourcen-Zuweisung etc. Das ist ein sehr schwieriges problem für die Menschen zu lösen, die aufgrund der sich rasch verändernden und vielfältige Umfeld, in dem Menschen operieren. Noch schlimmer zu machen, Menschen müssen oft schnell wichtige Entscheidungen treffen, noch bevor man die Gelegenheit, sammeln eine Menge Informationen, im Gegensatz zu dem Fall bei der Verwendung von deep-learning-Methoden, Modell-lernen und die Entscheidungsfindung in der künstliche-Intelligenz-Anwendungen.
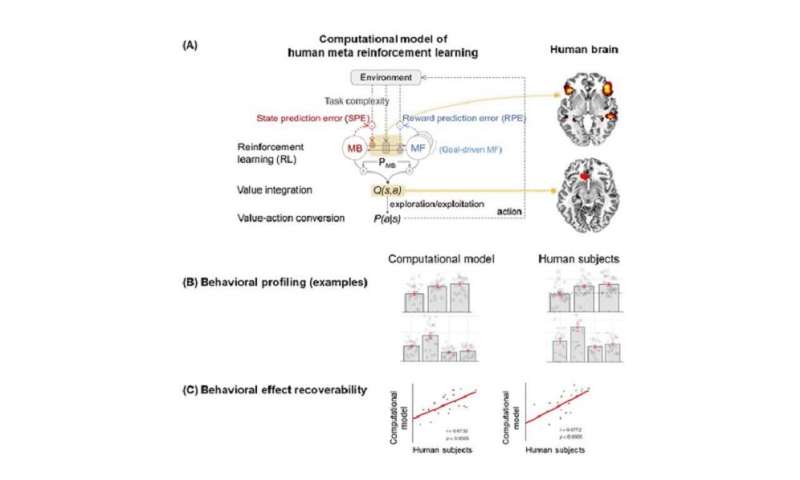
Um dieses problem zu lösen, das research-team verwendet eine Technik namens “reinforcement learning Theorie-basierten experiment design” zu optimieren, sind die drei Variablen der zwei-Stufen-Markov-Entscheidung, Aufgabe, Ziel, Aufgabe, Komplexität und die Aufgabe der Unsicherheit. Dieses experimentelle design Technik erlaubte es dem team nicht nur zu kontrollieren, Störfaktoren, aber auch um eine situation zu schaffen, ähnlich dem, was geschieht in der menschlichen Problemlösung.
Zweitens, das team verwendet eine Technik namens ” model-based neuroimaging analysis.’ Auf der Grundlage der erworbenen Verhaltens-und fMRT-Daten, mehr als 100 verschiedene Arten von meta-reinforcement learning-algorithmen wurden gegeneinander ausgespielt zu finden, ein Computer-Modell erklären können, dass sowohl Verhaltens-und neuronalen Daten. Drittens, im Interesse einer strengeren überprüfung, das team, eine analytische Methode namens ‘parameter-recovery-Analyse, welches umfasst Präzisions-Verhaltens-profiling sowohl die Menschen als auch Themen-und rechenmodellen.
Auf diese Weise war das team in der Lage, genau zu identifizieren, ein Computer-Modell des meta-reinforcement learning, gewährleisten nicht nur, dass das Modell offensichtlich Verhalten ist vergleichbar mit der des Menschen, aber auch, dass das Modell löst das problem auf die gleiche Weise wie Menschen es tun.
Das team fand heraus, dass Menschen eher zu erhöhen, plant-based reinforcement learning (genannt model-based control), in Reaktion auf die zunehmende Aufgabe der Komplexität. Jedoch, Sie Griff zu einem einfacheren, mehr Ressourcen-effiziente Strategie mit dem Titel ” model-free control, bei der sowohl die Unsicherheit und die Aufgabe, die Komplexität hoch. Dies deutet darauf hin, dass sowohl die Aufgabe, die Unsicherheit und die Aufgabe, Komplexität zu interagieren, während die meta-Steuerung von reinforcement learning. Computational fMRT-Analysen ergaben, dass die Aufgabe, die Komplexität interagiert mit neuronalen Repräsentationen der Zuverlässigkeit der Lernstrategien im inferioren präfrontalen Kortex.
Diese Befunde deutlich Voraus Verständnis von der Natur der Berechnungen umgesetzt, die in der inferioren präfrontalen Kortex während der meta-reinforcement learning sowie Einblicke in die allgemeinere Frage, wie das Gehirn löst Unsicherheit und Komplexität in einem sich dynamisch verändernden Umfeld. Identifizierung der key computational Variablen, die Fahrt präfrontalen meta-reinforcement learning kann auch darüber informieren, verstehen, wie dieser Prozess anfällig zu brechen in bestimmten psychiatrischen Erkrankungen wie Depressionen und Zwangsstörungen. Darüber hinaus gewinnt eine rechnerische Verständnis, wie dieser Prozess kann manchmal führen zu einem erhöhten model-free control kann einen Einblick in, wie unter bestimmten Umständen die Arbeitsleistung könnte brechen, unter Bedingungen hoher kognitiver Belastung.






